CATLISM, 274-278Text normalisation1CATLISM, 274-278#
Hint
In addition to the procedures documented below, normalisation of texts may include segmenting pieces of text where two or more words are grouped together; in such cases the procedure documented for the treatment of hashtags may be employed.
Normalisation of text files (.txt as well as .xml) can be achieved through VARD [], an interactive tool (written in Java) to conduct semi-automated normalisation. Originally designed for Early Modern English spelling variation, it can be adapted to (virtually) any type of variations through ready-made vocabularies (e.g. the online-language specific Twitter setup) or by creating a custom dictionary trained on a batch of the files to be normalised.
Further options and a user guide can be found in the tool official documentation.
Using the tool#
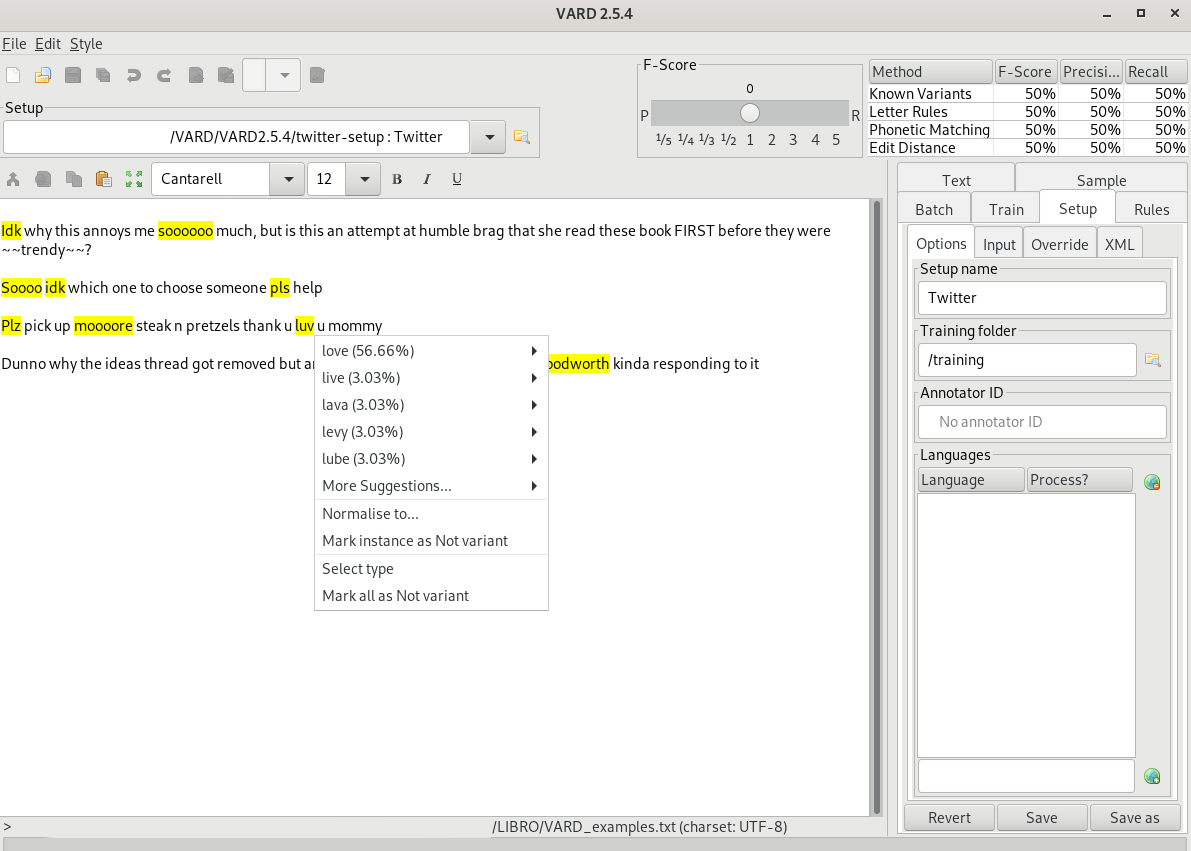
Figure 5.8 Example of recognised spelling variants in VARD#
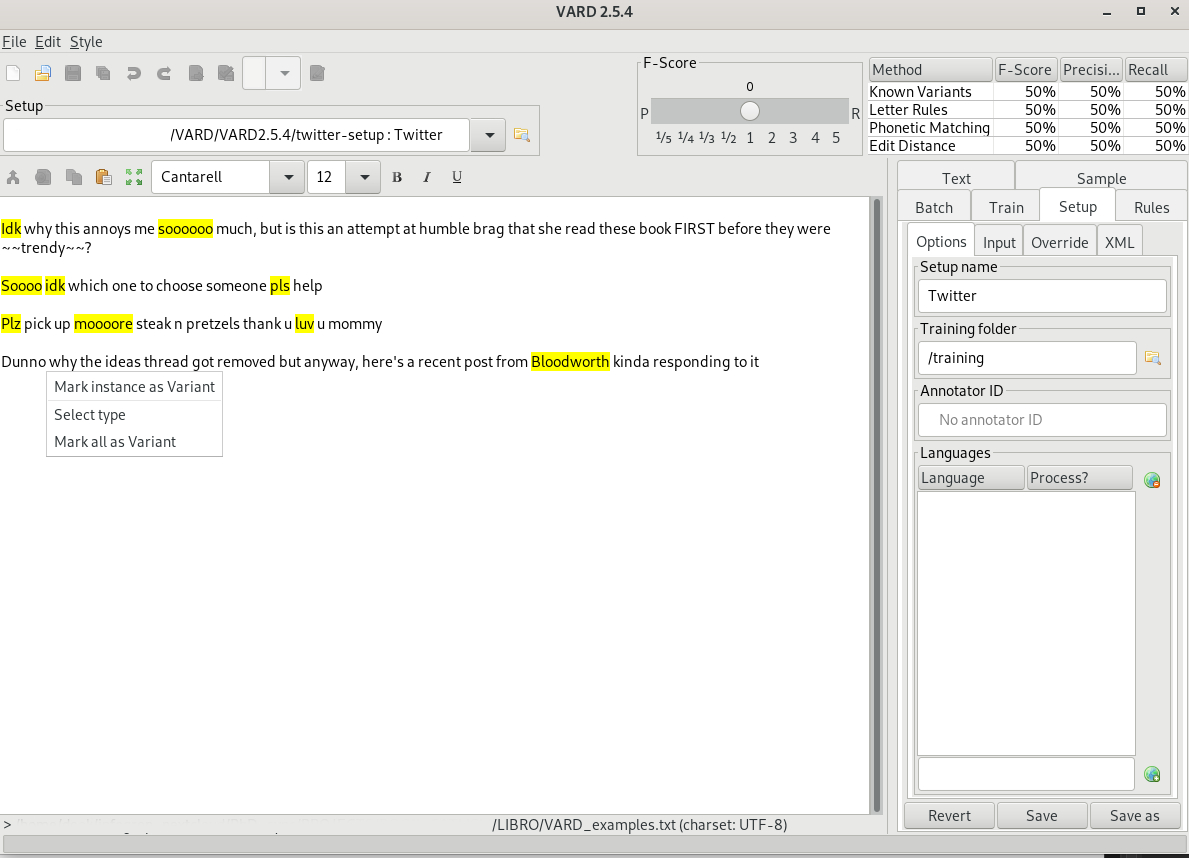
Figure 5.9 Example of unrecognised spelling variants in VARD#
Example of normalised data in XML format generated with VARD#
[e5.21]#<normalised orig="Plz" auto="false">Please</normalised>pick up<normalised orig="moooore" auto="false">more</normalised>steak<normalised orig="n" auto="false">and</normalised>pretzels thank<normalised orig="u" auto="false">you</normalised><normalised orig="luv" auto="false">love</normalised><normalised orig="u" auto="false">you</normalised> mommy