The communicative modus operandi of online child sexual groomers#
1www.swansea.ac.uk/project-dragon-s/2CATLISM, 350The case study [utilised] in this section is based on the research conducted at Swansea University Department of Applied Linguistics under the supervision of Prof. Nuria Lorenzo-Dus as part of the project ‘Online Grooming Discourse’ funded by EPSRC–CHERISH-DE and NSPCC (Lead Investigator: Prof. Nuria Lorenzo-Dus). In 2021 the project evolved into Project Dragon-S1www.swansea.ac.uk/project-dragon-s/ (Developing Resistance Against Grooming Online – Spot and Shield). Outputs from the research are published in [] and [], which served as basis for the contents [described].2
CATLISM, 350
CATLISM, 353-357Collecting the data from Perverted Justice3CATLISM, 353-357#
[s6.05] (adapted from [])# 1# Import modules for: regular expressions and for working with local files; List to enforce the type of data collected
2# (this is only required for Python < 3.9), and selected functions from Selenium
3import re
4import os
5from typing import List
6import pandas as pd
7from selenium.webdriver import Chrome
8from selenium.webdriver.common.by import By
9from selenium.webdriver.chrome.options import Options
10from selenium.common.exceptions import NoSuchElementException
11
12# Define the scraper as a class of objects
13class ChatLogScraper(object):
14 # Define the first function that sets the initial parameters: the starting URL, the regular expression to match the chatlog contents, as well as further options for Selenium
15 def __init__(self):
16 """Init function, defines some class variables."""
17 self.home_url = "http://www.perverted-justice.com/?con=full"
18
19 # Setup and compile the regular expression for later
20 master_matcher = r"([\s\w\d]+)[:-]?\s(?:\(.*\s(\d+:\d+:\d+\s[AP]M)\))?:?((.*)(\s\d+:\d+\s[AP]M)|(.*))"
21 self.chat_instance = re.compile(
22 master_matcher, re.IGNORECASE
23 ) # ignore case may not be necessary
24
25 # Instantiate the firefox driver in headless mode, disable all css, images, etc
26 here = os.path.dirname(os.path.realpath(__file__))
27 executable = os.path.join(here, "chromedriver")
28 # Set the headless command to run Firefox without a graphical interface
29 options = Options()
30 options.add_argument("--headless")
31 self.driver = Chrome(executable_path=executable, chrome_options=options)
32
33 # Define the 'start' function that searches and returns all the links found in the web pages and returns them as strings
34 def start(self) -> List[str]:
35 """Main function to be run, go to the home page, find the list of cases,
36 then send a request to the scrape function to get the data from that page
37
38 :return: list of links to scrap
39 """
40 print("loading main page")
41 self.driver.get(self.home_url)
42
43 main_pane = self.driver.find_element_by_id("mainbox")
44 all_cases = main_pane.find_elements(
45 By.TAG_NAME, "li"
46 ) # every case is under an LI tag
47 # We'll load the href links into an array to get later
48 links = []
49 for case in all_cases:
50 a_tags = case.find_elements(By.TAG_NAME, "a")
51 # The first a tag, is the link that we need
52 links.append(a_tags[0].get_attribute("href"))
53 return links
54
55 # Define the 'scrape_page' function which, starting from the previously collected URLs, parses the content of each chatlog page and extracts the username, content (statement) and timestamp of each message
56 def scrape_page(self, page_url: str) -> List[dict]:
57 """Go to the page url, use the regular expression to extract the chatdata, store
58 this into a temporary pandas data frame to be returned once the page is complete.
59
60 :param page_url: (str) the page to scrap
61 :return: pandas DataFrame of all chat instances on this page
62 """
63 self.driver.get(page_url)
64 try:
65 page_text = self.driver.find_element(By.CLASS_NAME, "chatLog").text
66 except NoSuchElementException:
67 print("could not get convo for", page_url)
68 return [] # Some pages don't contain chats
69 conversations = []
70
71 # Next, we'll run the regex on the chat-log and extract the info into a formatted pandas DF
72 matches = re.findall(self.chat_instance, page_text)
73 for match in matches:
74 # Clean up false negatives
75 if (
76 "com Conversation" not in match[0]
77 and "Text Messaging" not in match[0]
78 and "Yahoo Instant" not in match[0]
79 ):
80 username = match[0]
81 if match[4]:
82 statement = match[3]
83 time = match[4]
84 else:
85 statement = match[5]
86 time = match[1]
87 conversations.append(
88 {"username": username, "statement": statement, "time": time}
89 )
90 return conversations
91
92
93# The functions above are executed and the collected data is saved to a CSV file and a JSON file
94if __name__ == "__main__":
95 chatlogscrapper = ChatLogScraper()
96 conversations = []
97 links = chatlogscrapper.start()
98
99 try:
100 for index, link in enumerate(links):
101 print("getting", link)
102 conversations += chatlogscrapper.scrape_page(link)
103 finally:
104 conversations = pd.DataFrame(conversations)
105 conversations.to_csv("output.csv", index=False)
106 conversations.to_json("output.json")
CATLISM, 360-366Creating the final corpus4CATLISM, 360-366#
5CATLISM, 360Script
[s6.06]applies the steps described in sections ‘Emoticons’, ‘Duration and Turns’, and ‘Metadata’ to the collected CSV files and outputs an XML fle for each of them using the structure exemplified in[e6.08]5CATLISM, 360
[s6.06] # 1# Import (in order) the modules to: read/write CSV files; find files using regular expressions;
2# work with regular expressions; generate random strings; to generate random numbers; randomise data;
3# create dictionaries (the 'defaultdict' has the ability to handle missing data in dictionaries,
4# in contrast to Python's default dictionary); read/write XML files
5import csv
6import glob
7import re
8import string
9from random import randint
10import random
11from collections import defaultdict
12from lxml import etree
13
14# List all CSV files in the current folder
15csvfiles = glob.glob("*.csv")
16
17# Create two dictionaries: one ('user_types_dict') to store usernames mapped against their 'role' (g = groomer, d = decoy);
18# the other ('timings_dict') to store usernames mapped against the total amount of time it interacted with one or more decoys
19user_types_dict = defaultdict(list)
20timings_dict = defaultdict(list)
21
22# Open the metadata file (named .cs to avoid being read as a CSV chat log file) and read it as a csv file
23metadata_file = csv.reader(
24 open("metadata_file.cs", "r", encoding="utf-8"), delimiter="\t"
25)
26# For each row, do:
27for row in metadata_file:
28 # Read the username and its role and add the information to the dictionary 'user_types_dict'
29 user_types_dict[row[0].lower()].append(row[1])
30 # Read the total amount of time a groomer interacted with a decoy, and assign the value to the dictionary 'timings_dict'
31 timings_dict[row[0].lower()].append(row[2])
32
33
34# Create a function to add the type (g or d) to the username passed to the function during the data processing
35def get_user_type(text):
36 # Read the username, convert it to lowercase, and store it in the variable 'user'
37 user = text.lower()
38 # If 'user' is found in 'user_types_dict', extract its type label and store it in the variable 'usertype'
39 if user in user_types_dict:
40 usertype = str(user_types_dict[user][0])
41 # Else if not found, assign the value 'na' to the variable 'usertype'
42 else:
43 usertype = "na"
44 # Output the value of 'usertype'
45 return usertype
46
47
48# Create a function to add the total time of interaction to the corpus during the data processing, using the same rationale and
49# operations employed in 'get_user_type'
50def get_user_timing(text):
51 username = text.lower()
52 if username in timings_dict:
53 timing = str(timings_dict[username])
54 else:
55 timing = "na"
56 return timing
57
58
59# Build the emoticons conversion steps; adapted from the emoticons.py function by Brendan O'Connor
60# https://github.com/aritter/twitter_nlp/blob/65f3d77134c40d920db8d431c5c6faef1c051c94/python/emoticons.py
61# Define the regular expression that will be used during the data processing to identify emoticons
62regex_compile = lambda pat: re.compile(pat, re.UNICODE)
63# Define the characters for eyes, nose, mouth to be used in the regular expressions; each
64NormalEyes = r"[:=]"
65Wink = r"[;]"
66NoseArea = r"(|o|O|-)"
67HappyMouths = r"[D\)\]]"
68SadMouths = r"[\(\[]"
69KissMouths = r"[\*]"
70Tongue = r"[pP]"
71
72# Construct the possible combinations into regular expressions
73happysmiley_regex = (
74 "("
75 + NormalEyes
76 + "|"
77 + Wink
78 + ")"
79 + NoseArea
80 + "("
81 + HappyMouths
82 + "|"
83 + Tongue
84 + ")"
85)
86sadsmiley_regex = "(" + NormalEyes + "|" + Wink + ")" + NoseArea + "(" + SadMouths + ")"
87kisssmiley_regex = (
88 "(" + NormalEyes + "|" + Wink + ")" + NoseArea + "(" + KissMouths + ")"
89)
90# Compile the regular expressions using the previously defined 'regex_compile'
91happysmiley_compile = regex_compile(happysmiley_regex)
92sadsmiley_compile = regex_compile(sadsmiley_regex)
93kisssmiley_compile = regex_compile(kisssmiley_regex)
94
95# Define the root <corpus> XML element tag of the output file
96corpus = etree.Element("corpus")
97
98# For each CSV chat log file, do:
99for csvfile in csvfiles:
100 # Create the <text> root element tag as child of the <corpus> root element
101 text_tag = etree.SubElement(corpus, "text")
102
103 # Create a function to generate a random ID using the 'random_number' variable (defined further below), plus a
104 # set of randomly chosen letters
105 def id_generator(N):
106 return "".join(
107 random.choices(
108 string.ascii_uppercase + string.ascii_lowercase + string.digits, k=N
109 )
110 )
111
112 # Generate a random number to be used for the creation of the unique <text> ID
113 random_number = str(randint(0, 100000000))
114 # Generate a random ID and assign it as value of the <text> attribute 'id'
115 text_tag.attrib["id"] = str(id_generator(10) + random_number)
116
117 # Create an empty list to store the usernames found in the chat log
118 usernames_list = []
119
120 # Open the chat log file and read it as a csv file
121 input_csv = csv.reader(open(csvfile, "r", newline="", encoding="utf-8"))
122 # Store the filename without extension inside the variable 'filename_without_csv'
123 filename_without_csv = csvfile.replace(".csv", "")
124 # Skip the first line of the CSV chat log file containing the columns header
125 next(input_csv, None)
126 # Iterate over each row and store them inside of the variable 'rows'
127 rows = [r for r in input_csv]
128 # For each row, count its position (starting from 1; this is equal to the turn number in the chat) and store it in
129 # the variable 'line_number', then do:
130 for line_number, row in enumerate(rows, start=1):
131 # Create the <u> element tag for the chat turn (i.e. the chat message)
132 turn_tag = etree.SubElement(text_tag, "u")
133 # Assign the row position in the csv file as value of the <u> attribute 'turn'
134 turn_tag.attrib["turn"] = str(line_number)
135 # Read the username from the first column of the chat log file, clean it from any potential leading or trailing whitespace,
136 # and assign it as value of the <u> attribute 'username'
137 turn_tag.attrib["username"] = str(row[0]).strip()
138 # Write the username (without any potential whitespace) to the list of usernames for this chat log
139 usernames_list.append(str(row[0]).strip())
140 # Read the timestamp from the third column of the chat log file and assign it as value of the <u> attribute 'time'
141 turn_tag.attrib["time"] = str(row[2])
142 # Read the date on which the message was sent from the fourth column of the chat log file, and assign it as value of
143 # the <u> attribute 'date'
144 turn_tag.attrib["date"] = str(row[3])
145 # Using the 'get_user_type' function with the username as input, extract the type of user and assign it as value of the
146 # <u> attribute 'usertype'
147 turn_tag.attrib["usertype"] = get_user_type(str(row[0]).strip())
148 # Read the chat message from the second column of the chat log file and store it inside a variable
149 message = row[1]
150 # Test for the presence of emoticons in the message using the three previously compiled regular expressions, and if found substitute it with the respective substitution-label (§_HAPPY-SMILEY_§, §_SAD-SMILEY_§, or §_KISS-SMILEY_§)
151 if happysmiley_compile.search(message):
152 message = re.sub(happysmiley_compile, " §HAPPY-SMILEY§ ", message)
153 elif sadsmiley_compile.search(message):
154 message = re.sub(sadsmiley_compile, " §SAD-SMILEY§ ", message)
155 elif kisssmiley_compile.search(message):
156 message = re.sub(kisssmiley_compile, " §KISS-SMILEY§ ", message)
157 # Assign the formatted message as text of the <u> element tag
158 turn_tag.text = message
159
160 # Read all the unique values in the list of usernames, and for each one do:
161 for username in set(usernames_list):
162 # Get the user type
163 user_type = get_user_type(username)
164 # If the user type is equal to 'g' (i.e. groomer), get the total amount of time they spent chatting and assign it to
165 # the <text> attribute 'timing', and add the groomer's username as value of the <text> attribute 'user'
166 if user_type == "g":
167 text_tag.attrib["timing"] = re.sub(
168 "(\[|\]|')", "", get_user_timing(username)
169 )
170 text_tag.attrib["user"] = username
171
172# Create the XML structure by adding all the extracted elements to the main 'corpus' tag
173tree = etree.ElementTree(corpus)
174# The resulting XML structure is written to the XML file named after the original CSV chat log file using utf-8 encoding,
175# adding the XML declaration at the beginning and graphically formatting the layout ('pretty_print')
176tree.write(
177 filename_without_csv + ".xml",
178 pretty_print=True,
179 xml_declaration=True,
180 encoding="utf-8",
181)
CATLISM, 352-353Sample from the final corpus6CATLISM, 352-353#
[e6.08]# 1<?xml version='1.0' encoding='UTF-8'?>
2<corpus>
3 <text id="dz1cVUMyIB99080150" timing="1333" user="luv2licku68">
4 <u turn="1" username="luv2licku68" time="8:54:50 PM" date="04112010" usertype="g"> hey there, how are you doing?</u>
5 <u turn="2" username="katierella1013" time="8:54:01 PM" date="04112010" usertype="d"> hi a/s/l? §_HAPPY-SMILEY_§ </u>
6 ...
7 <u turn="19" username="katierella1013" time="8:59:13 PM" date="04112010" usertype="d">
8 well i
9 <normalised orig="dunno" auto="true">don't know</normalised>
10 , like the stuff some people say and there's like so much going on, so many conversations
11 <normalised orig="n" auto="true">and</normalised>
12 stuff
13 </u>
14 </text>
15 ...
16</corpus>
CATLISM, 368Example of the interactive plot created for the visual exploration of collocations7CATLISM, 368#
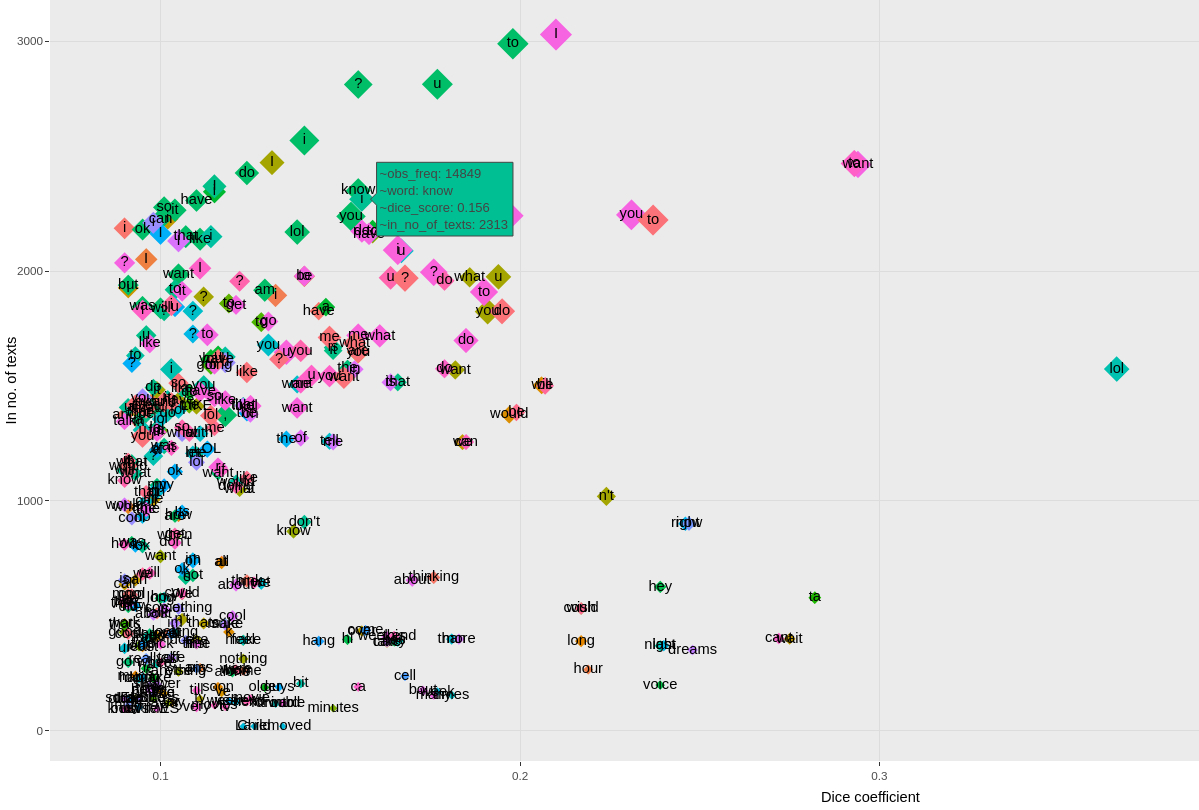
Figure 6.3 Example of the interactive plot created for the visual exploration of collocations#
Consult the original interactive plot