#LancsBox#
Originally developed for the analysis of corpora, #LancsBox has later implemented the ability to create corpora by providing a list of URLs to scrape. Only this latter functionality is documented here (and in the book).
Options and instructions for the tool can be found in the official documentation.
CATLISM, 148Data collection functionality is accessed by clicking on the ‘Create Corpus’ option in the #LancsBox main interface page (Figure 5.1). The scraping window (Figure 5.2) opens, and after the corpus name (a) and list of URLs to collect (b) are defined, a number of scraping options can be adjusted: these include the maximum number of pages to collect (c; the default value is 100) and the maximum depth of collection (d; default value is 2). This latter option indicates whether #LancsBox should also collect pages from URLs linked in the specified URLs. Additionally, #LancsBox can be set to collect pages linked in the collected pages that are outside of the domain specified by the provided URLs (e; set of by default). Last, the ‘Heuristics settings’ (f) can be employed to collect pages whose URLs follow sequential numbering (‘Page number’) or include a date (‘Date’) – such as the ones created by WordPress blogs – by defining the start number/date (g) and the maximum value/date (h); the crawler then uses predefined or custom (i) regular expressions […] to discover and retrieve the data. The collected data is then processed by #LancsBox, which applies tokenisation, POS tagging, and lemmatisation through TreeTagger […] and creates a new corpus to be analysed with #LancsBox corpus functionalities.1
CATLISM, 148
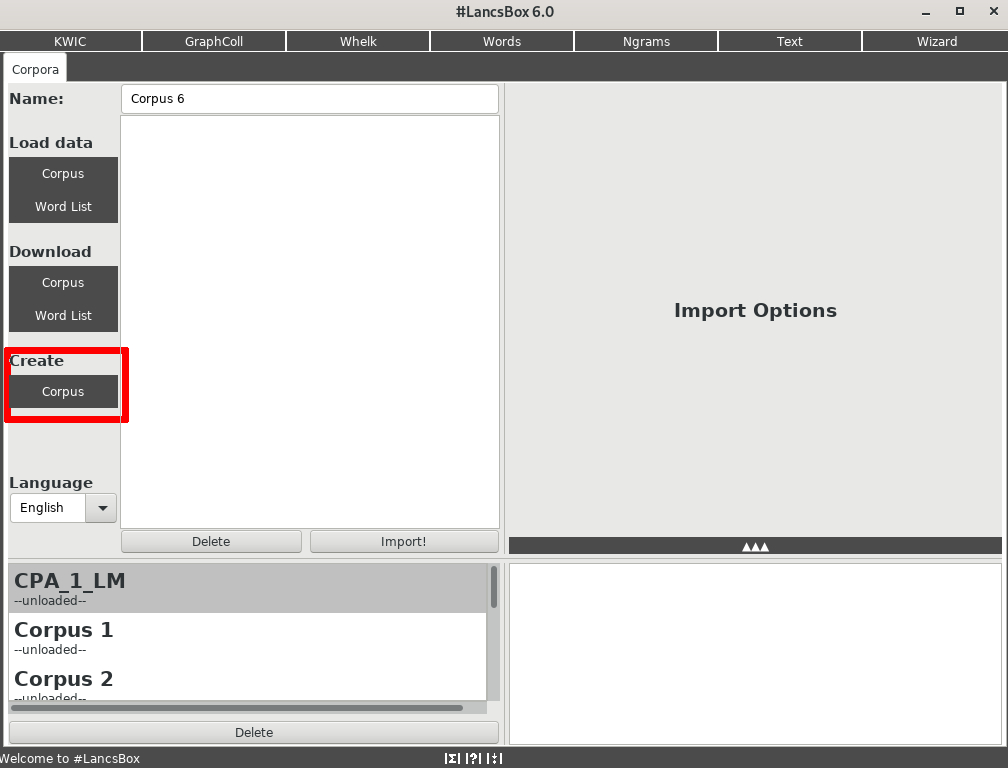
Figure 5.1 #LancsBox main interface#
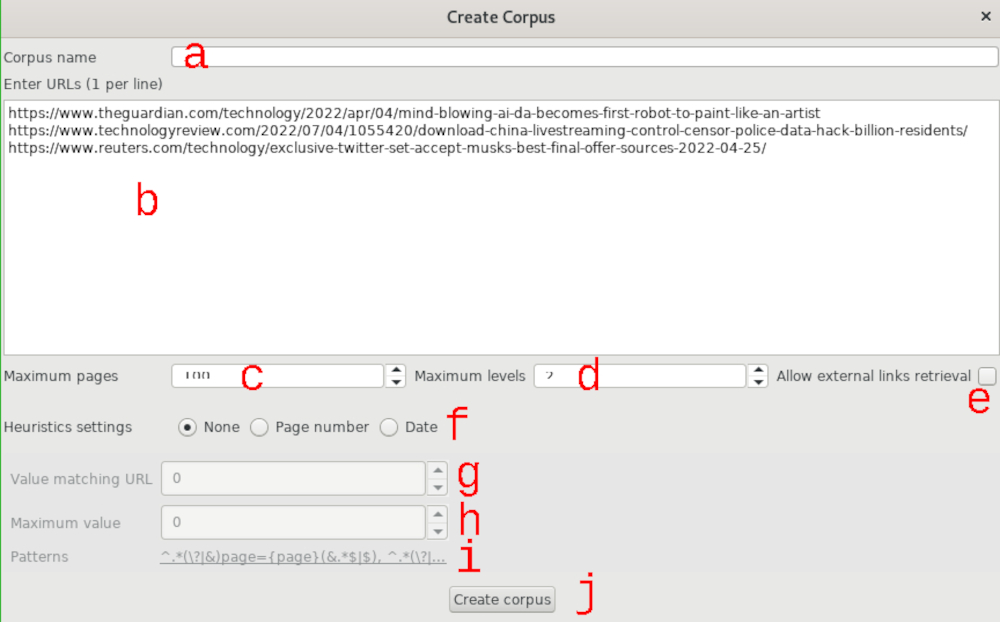
Figure 5.2 #LancsBox data collection interface#