Archivebox#
Data collection from websites can be obtained using Archivebox.
Options and arguments for the tool can be found in the official documentation.
CATLISM, 152Installing the tool1CATLISM, 152#
Command
[c5.01]#pip install archivebox
[c5.01]
CATLISM, 153Using the tool2CATLISM, 153#
Command
[c5.02]#archivebox init --setup
Command
[c5.03]#archivebox server
In the video, a local folder for storing archivebox settings and downloaded data is created through the command mkdir archivebox_folder, only available in Unix-like systems ( and ).
Windows user should instead employ md archivebox_folder ().
Once [c5.03] is issued, it is possible to access the web application by browsing the address htpp://127.0.0.1:8000 (as indicated in the CLI).
[c5.02-03]
CATLISM, 153-155Extracting the data3CATLISM, 153-155#
Figure 5.3 Archivebox main page#
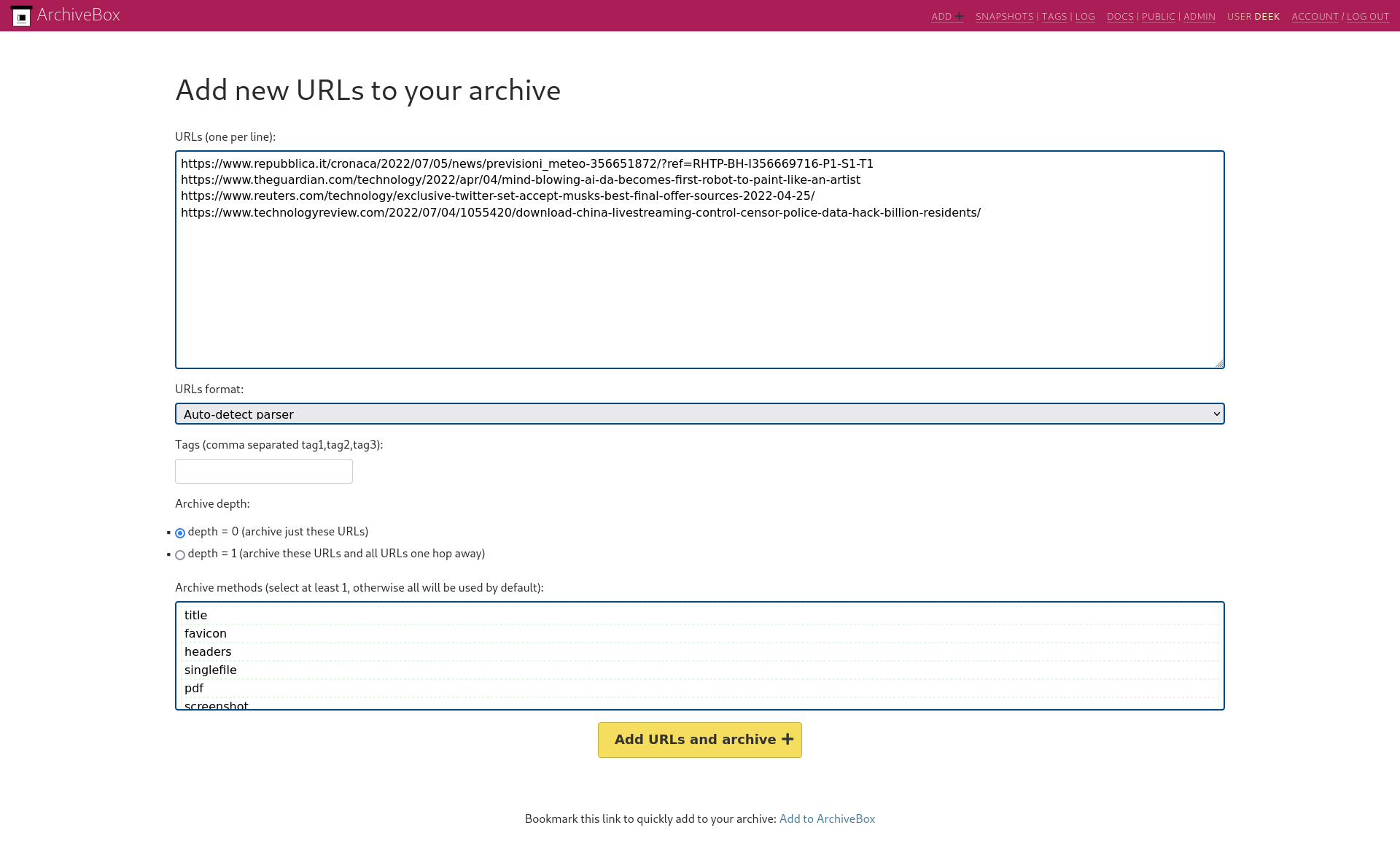
Figure 5.4 Archivebox URLs collection page#
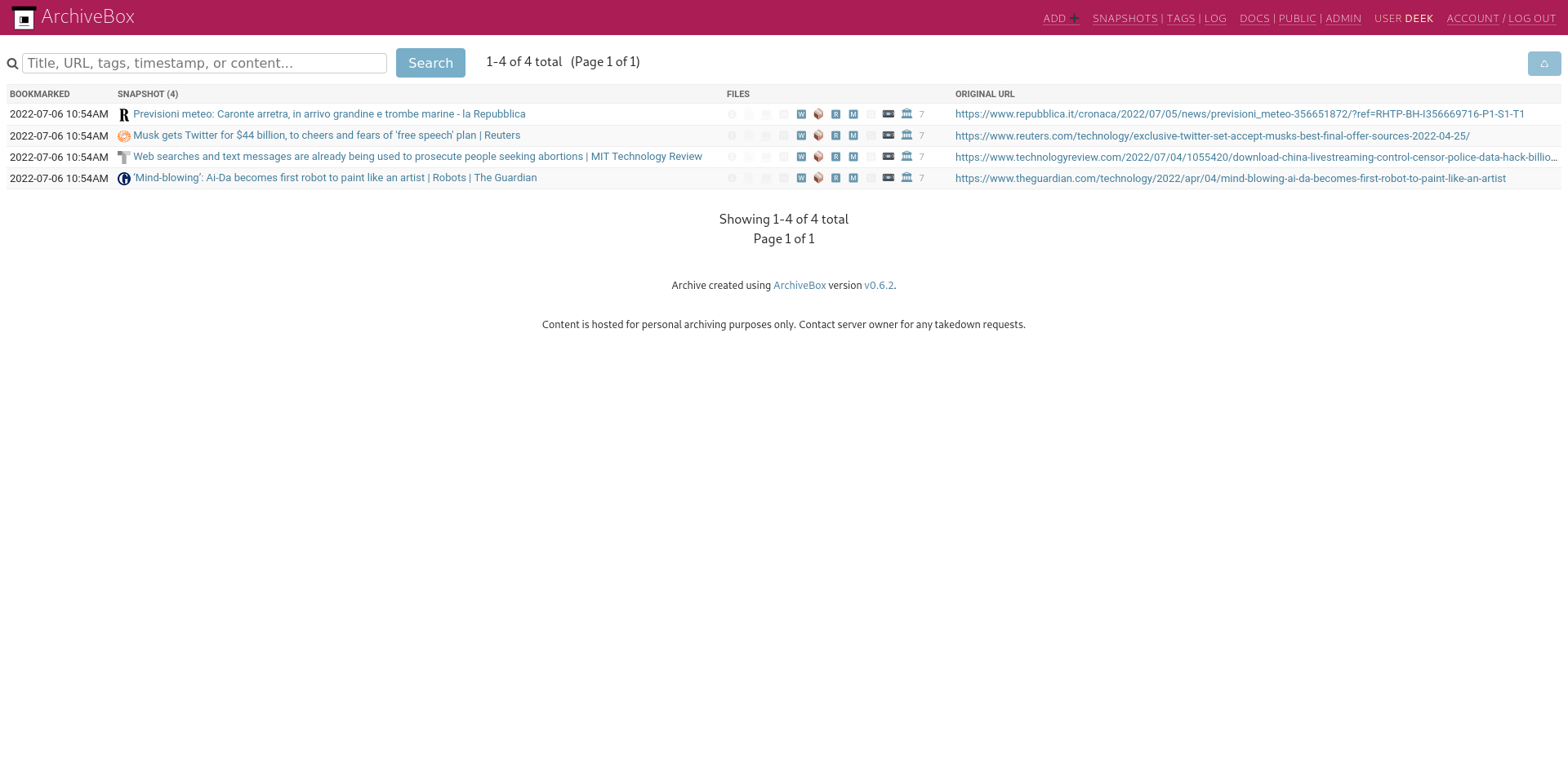
Figure 5.5 Archivebox main page showing the list of collected web pages#